
We can better understand the role of machine learning techniques through a very simple definition given by professor Mitchell −
‘A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.’ Based on this definition, the Machine Learning Model can be given as shown in Fig. 2.5. Here,
Task(T), is the real-world problem to be solved. For example, predicting sales of a product, classifying an email as spam or not a spam, etc. Technically, examples of ML based tasks are classification, regression, clustering, recognition, etc.
Experience (E) is the knowledge gained from data provided to the algorithm or model. Once data is provided, the model runs iteratively to learn some inherent patterns. Therefore, like humans, machines now learn from experience by analysing situation, relationships etc. Supervised, unsupervised and reinforcement learning are some ways to learn or gain experience. Experience acquired through ML model or algorithm is used to solve task T.
Performance (P) is a measure that indicates how well a particular ML algorithm has performed the given task T using experience E. Performance is analysed based on well-defined metrics including accuracy, F1, confusion matrix, precision, recall, sensitivity, etc.
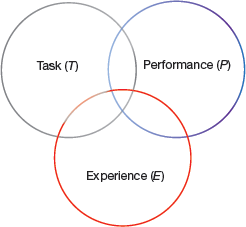
FIGURE 2.5 ML Model is a combination of Task, Performance and Experience
2.2.1 Types of Machine Learning Algorithms
Machine learning algorithms can be categorized as supervised or unsupervised.
2.2.1.1 Supervised Machine Learning Algorithms
As the name indicates, such algorithms have a supervisor as teacher. These algorithms apply learning from past data (or experiences) to new data using labelled examples.
Technically, supervised learning algorithms learn an association between input data and output. For example, if we have input variable(s) X and output variable (Y), then the mapping function from input to output can be given as, Y=f(x). This mapping function can be used to predict the output value for any new input after learning from the existing data.
For example, if you have a basket filled with different varieties of fruits then the first step is to train the machine to identify a fruit. Now, our machine can easily identify an apple and a banana. Supervised learning algorithms can be further classified into two categories:
Supervised learning should be used when output of data in the training set is known.
Classification Algorithm
A classification algorithm classifies data into a particular group. Classification techniques predict discrete categories. The output will be based on what the model has learned in training phase.
For example, a fruit as either an apple or a banana. In real world applications, classification can be used in medical imaging, speech recognition, hand-writing recognition, credit scoring, predict if an incoming email is authentic or spam, or whether a tumour is cancerous or benign.
Classification algorithms are best used if data can be tagged, categorized, or separated into specific groups or classes.
Regression
A regression algorithm predicts a real value. The output value is based on what the model has learned in its training phase. In contrast to classification algorithms, regression predict continuous values. For example, the cost of a product, the value of a stock, changes in temperature or fluctuations in power demand.
Thus, in supervised machine learning algorithm, data input and desired output, along with a feedback about the accuracy of predictions during algorithm training are provided. Data scientists can select variables or features that can be used by the model to analyse data and make predictions. For example, supervised learning can be used by a company to identify customers who are likely to churn. It can also be used by insurance companies to predict the likelihood of occurrence of a mishap and determine the total insurance value.
In supervised learning, clear instructions are given specifying what needs to be learnt and how it needs to be learnt.
2.2.1.2 Unsupervised Learning
Unsupervised learning trains the machine using information that is neither classified nor labelled. In this case, the machine learning algorithm works on that information without any guidance. The unsorted information is grouped based on similarities, patterns and differences without any prior training of data. For example, if we give an image of mango and an orange, then initially, the machine has no idea about how a mango looks and how the orange looks.
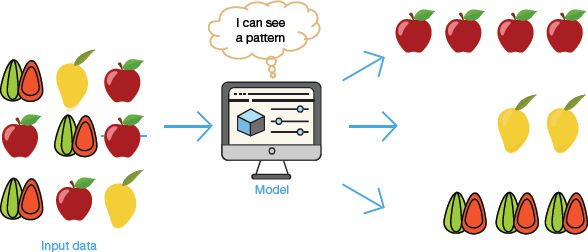
FIGURE 2.6 Grouping fruits by identifying patterns
Unsupervised machine learning algorithm learns through observation and finding structures in the data. That is, the model automatically finds patterns and relationships in the dataset by creating clusters in it. For example, if given a dataset of pictures of both mangoes and oranges, the algorithm can make two clusters- one containing only pictures of oranges and the other of mangoes (refer Fig. 2.6). What an unsupervised machine learning cannot do is specifying labels to the clusters. That is, it can only segregate the pictures but cannot tell that this is a real-world orange and that is a mango.
Unsupervised learning can be categorized into following sets of algorithms:
- Clustering: In clustering, the aim is to discover inherent groupings in the data or discover hidden patterns (refer Fig. 2.7). It is one of the most useful unsupervised machine learning techniques as it finds similarity as well as relationship in the underlying data. For example, a company may like to group its customers by their purchasing behaviour. A cell phone company can use clustering to optimally decide the locations where they can build cell phone towers (these clusters can depict the number of people relying on their towers). Other applications include gene sequence analysis, market research, and object recognition.
- Association analysis: In association mining (or analysis), the aim is to discover rules that describe large portions of data. For example, a company can use association analysis to conclude that customer who buys X also buys product Y.
- Dimensionality reduction: It is used to reduce the number of feature variables for the data set. It is done by selecting a set of principal or representative features. Dimensionality reduction is very important technique especially when the data set has a large number (millions).
- Outlier detection or anomaly detection: This technique is used to find out the occurrences of rare events or observations that generally do not occur. Application of learned knowledge in anomaly detection techniques helps to differentiate between anomalous or a normal data point. Generally, clustering (more specifically, KNN) is used to detect anomalies based in data.
Thus, unsupervised machine learning algorithms (also called neural networks) are used when the information used to train is neither classified nor labelled. These algorithms use an iterative approach called deep learning to review data and arrive at conclusions. Unsupervised learning algorithms are used for more complex tasks than supervised learning systems. For example, these algorithms are used in image recognition, speech-to-text and natural language processing applications, predict the probability of presence of a particular disease. A retailer can use unsupervised learning technique to find out products that are frequently bought by customers tends to buy more frequently.
FIGURE 2.7 In supervised learning, we have some clue about what exactly we are finding but unsupervised learning explores data to find just any hidden pattern
2.2.1.3 Semi-Supervised Learning
Semi-supervised machine learning algorithms fall somewhere between supervised and unsupervised algorithms since they use both labelled and unlabelled data for training. These algorithms improve accuracy.
Semi-supervised learning algorithms use small amount of pre-labelled data and a large number of unlabelled data for training. Semi-supervised learning techniques can be applied using any of the two approaches given below.
First, to build the supervised model based on small amount of labelled data followed by building an unsupervised model by applying the same to the large amounts of unlabeled data. Experience gained by generating more labelled data is used to train the model. This process is repeated multiple times.
In the second approach, unsupervised methods are used to cluster similar data samples, annotate these groups and then use this information to train the model.
Application of the discussed techniques can be summarized in the flowchart given in Fig. 2.8 below.
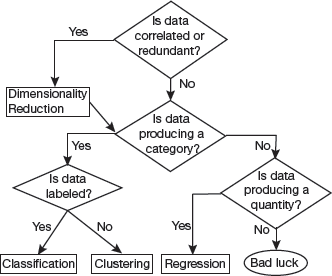
FIGURE 2.8 Summary of ML Algorithms
2.2.1.4 Reinforcement Learning (Rl)
These techniques are different from the previously discussed techniques and are rarely used. In a reinforcement learning algorithm, an agent is trained over a period of time so that it can interact with a specific environment.
Reinforcement learning, is a type of dynamic programming that trains algorithms using a system of reward and punishment. The agent receives rewards by performing correctly and penalties for performing incorrectly. In this way, the agent learns without any human intervention to maximize its reward and minimize its penalty.
Since RL requires a lot of data, it is mostly used in areas where simulated data is readily available like gameplay and robotics. In these areas, RL is used to find the best possible behaviour or path that can be taken in a particular situation.
Reinforcement learning is different from supervised learning. In supervised learning, the training data has labels, so the model is trained with the correct answer but in case of RL, the reinforcement agent decides what to do to perform the given task. In the absence of a training dataset, it is bound to learn from its own experience.
Example: In the game shown in Fig. 2.9, there is an agent (robot) and a reward (diamond), with many hurdles (fire) in between. The robot has to learn by trying all the possible paths and then choose the path that gives him the reward with the least hurdles. Each right step earns a reward and every wrong step will subtract the reward of the robot. The total reward is calculated when it reaches the final reward that is the diamond.
To summarize technically, in an RL algorithm, note the following:
- Input is an initial state from which the model will start
- Output is a list of possible outputs for a particular problem
- Training is based on the input. The model returns a state and the user will decide to reward or punish the model based on its output. The model keeps learning this way until it finds the best solution (or the solution with maximum reward).

FIGURE 2.9 Robot and the Reward Game
2.2.1.4.1 Types of Reinforcement
There are two types of reinforcement as follows:
Positive reinforcement has a positive effect on behaviour. It occurs when a particular behaviour, increases the strength and the frequency of the behaviour. Such a reinforcement maximizes performance and sustain changes for a long period of time.
Negative reinforcement is defined as strengthening a behaviour by stopping or avoiding a negative condition.
2.2.1.4.2 Applications of Reinforcement Learning
RL is used in large environments when a model of the environment is known, but an analytic solution is not available.
- RL can be used in robotics for industrial automation.
- It is used to make machines learn
- RL is used in data processing applications
- RL can be used to create training systems that provide custom instruction and materials according to the requirement of students.
- RL is used for creating game playing software (playing chess).
- RL is used in a self-driving car where the car (agent) interacts with its environment, receives a reward depending on how it performs, such as driving to destination safely. Similarly, the agent receives a penalty for performing incorrectly, such as going off the road or hitting a hurdle.
An RL agent perceives and interprets its environment, takes actions and learns through trial and error.
Leave a Reply