
Like decision trees, random forests are also a versatile machine learning technique that can perform both regression and classification. They give better performance than decision trees as it does everything for reducing the number of dimensions (or variables), treating missing values, outlier values and exploring data.
Random forests perform better than bagged trees as it de-correlates the trees. Like in bagging, random forests also create a number of decision trees on training data sets. For creating these trees, each split considers a random sample of m predictors as split candidates from the full set of predictors. A split uses only one of those m predictors. Therefore, the main difference between bagging and random forest is that while bagging chooses all predictors, random forest selects only one of the m predictors.
Let us summarize the possibilities.
- If the number of cases in the training set is K, then a random sample of these K cases is taken as the training set.
- Out of p input variables, specify a number m, such that m < p. At each node, m random variables out of p predictors are chosen. The best split on these m variables is used to split the node.
- Each tree is subsequently grown to the largest extent possible
- Take the average of all the predictions made by the target trees to finally predict new data.
- To classify a new object based on attributes, each tree gives a classification and finally the classification occurring most frequently is chosen.
In simpler terms, we can understand the working of a random forest in the following steps.
Step 1: Random samples are selected from a given dataset.
Step 2: A decision tree is constructed for each sample to obtain a prediction result from each decision tree as shown in Fig. 2.19.
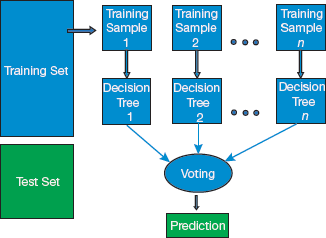
Step 3: Voting for each predicted result is performed.
Step 4: Prediction result with the maximum votes is selected as the final prediction.
Other major advantages of using Random forests include the following:
- It can be very effectively used to estimate missing data
- It maintains accuracy when a large proportion of the data is missing
- It can balance errors in datasets where the classes are imbalanced
- It can handle huge datasets with large number of dimensions
Limitations
- Random forests might easily overfit noisy datasets, especially when performing regression.
- Each tree is grown to the largest extent possible without pruning.
- Random forests are slow in generating predictions as multiple decision trees are constructed and then the process of voting selects the best prediction result.
- Random forests are difficult to interpret as and when compared to a decision tree model.
Leave a Reply