
Convolutional neural networks are a special type of neural network that roughly imitates human vision. Initially, they were used to recognize handwritten digits and were especially used in the postal sectors to read zip codes, pin codes, etc. as shown in Fig. 6.12. A CNN requires a large amount of data and computing resources to train.
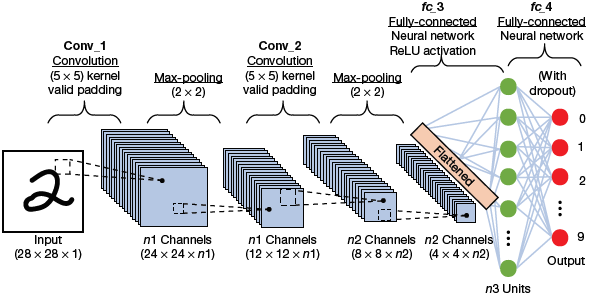
FIGURE 6.12 Classic computer vision
CNN is a branch of deep learning that uses multi-layered neural networks to analyse visual imagery. For this, CNN uses a special technique called convolution. Convolution is a mathematical operation on two functions that produces a third function that expresses how the shape of one is modified by the other.
Credit: NERAMIT SISA / Shutterstock
We will not discuss the mathematics part required to understand how a CNN works. Just understand that a CNN is a composition of three main types of layers (refer Fig. 6.13).
Convolution layer, which is the primary building block and performs computational tasks based on convolution function.
Pooling layer, that is arranged next to convolution layer and is used to reduce the size of inputs by removing unnecessary information to speedup computations without losing features that are critical for getting a good prediction.
Fully connected layer, arranged next to series of convolution and pooling layer to classify input into various categories.
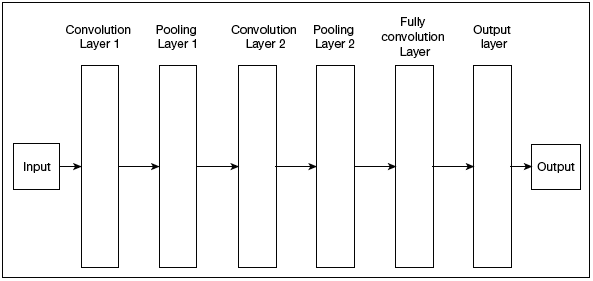
FIGURE 6.14 Convolution neural network
In Fig. 6.14, there are two series of convolution and pooling layer. The convolution layer receives and process the input to produce the output.
6.10.1 Understanding the Working of a Simple CNN
Convolution is a simple mathematical operation that can be applied on image processing operators. Convolution can be done by multiplying two arrays (or lists) of numbers, to produce a third array (or list) of numbers of the same dimensionality.
An image convolution is an element-wise multiplication of image arrays and another array called the kernel followed by sum.
For simplicity, let us consider a grayscale image that is represented as a pixel of values.
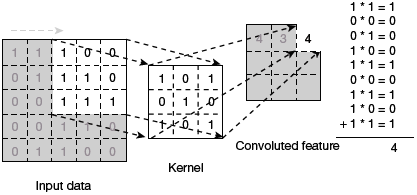
FIGURE 6.15 Kernel Layer for Filtering or Manipulating Images
In Fig. 6.15, we have taken a filter by using a kernel layer comprising of 3×3 matrix. The kernel layer is applied to the input image to get the convolved feature. This convolved feature is passed on to the next layer.
Thus, we see that a CNN consists of multiple layers of artificial neurons that calculates weighted sum of multiple inputs in order to output an activation value. When an image is input in a CNN, each layer generates several activation functions that are then passed on to the next layer. For example, the first layer extracts basic features such as horizontal or diagonal edges. This output is passed on to the next layer which detects more complex features such as corners or combinational edges. More layers in the network can be used to identify even more complex features such as objects, faces, etc.
Activation map (also known as feature map) generated by the final convolution layer guides the classification layer to produce a set of confidence scores (values between 0 and 1) indicating how likely the image is to belong to a particular class.
Therefore, a CNN need not be limited to only one convolutional layer. The first convolution layer captures low-level features such as edges, color, gradient orientation, etc. Subsequent layers can extract other high-level features that gives a wholesome understanding of images in the dataset. In the convolution layer, several kernels are used to produce several features.
The activation or the feature map can then be used to
- reduce the image size so that it can be processed more efficiently.
- focus on certain features of the image that can help in processing the image further. For example, to recognize a person, we may need to focus on a person’s eyes, nose and mouth to recognize the person rather than focusing on the entire face.
6.10.2 THE Pooling Layer
The convolution layer is followed by a pooling layer that can be of two types—average pooling and max pooling.
Max pooling finds the maximum value of a pixel from a part of the image covered by the kernel. It discards the noisy activations thereby performing de-noising along with dimensionality reduction.
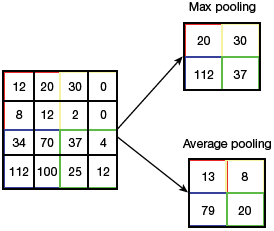
FIGURE 6.16 Pooling Techniques
Average Pooling returns the average of all the values from the part of the image covered by the Kernel. Max Pooling performs better than Average Pooling.
The two techniques of pooling can be better understod from Fig. 6.16.
6.10.3 Limitations
The advent of CNN has revolutionized the field of AI in a big way. A CNN gives in-depth results and recognizes even minute patterns and details that otherwise goes unnoticed to the human eye. However, even after using great amount of computing power while being trained with massive amount of data, CNN were not able to completely identify, block and remove inappropriate content from social media.
CNN also fails to detect objects when they are seen under different lighting conditions and presented from new angles. Table 6.1 highlights the differences between a CNN and a neural network, often referred to as ANN or artificial neural network.
TABLE 6.1 Differences between CNN and ANN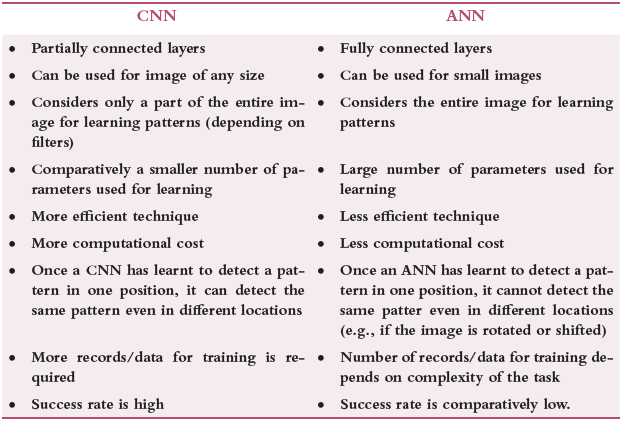
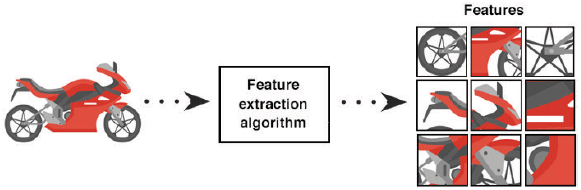
Application Example of Image Features
In computer vision and image processing, a feature is a piece of information that is required to solve a computational task in context to a given application. These features may be points, edges or objects (refer Fig. 6.17). For example, if given six small patches of images, we can make our algorithm identify location of those image patches in the image. Once developed, we can use this algorithm to find similar images in a huge dataset of images.
Leave a Reply