Now as we saw in Chapter 1, NLP was an early focus for AI researchers. But because of the limited computer power, the capabilities were quite weak. The goal was to create rules to interpret words and sentences—which turned out to be complex and not very scalable. In a way, NLP in the early years was mostly like a computer language!
But over time, there evolved a general structure for it. This was critical since NLP deals with unstructured data, which can be unpredictable and difficult to interpret.
Here’s a general high-level look at the two key steps:
- Cleaning and Preprocessing the Text: This involves using techniques like tokenization, stemming, and lemmatization to parse the text.
- Language Understanding and Generation: This is definitely the most intensive part of the process, which often uses deep learning algorithms.
In the next few sections, we’ll look at the different steps in more detail.
Step #1—Cleaning and Preprocessing
Three things need to be done during the cleaning and preprocessing step: tokenization, stemming, and lemmatization.
Tokenization
Before there can be NLP, the text must be parsed and segmented into various parts—a process known as tokenization. For example, let’s say we have the following sentence: “John ate four cupcakes.” You would then separate and categorize each element. Figure 6-1 illustrates this tokenization.
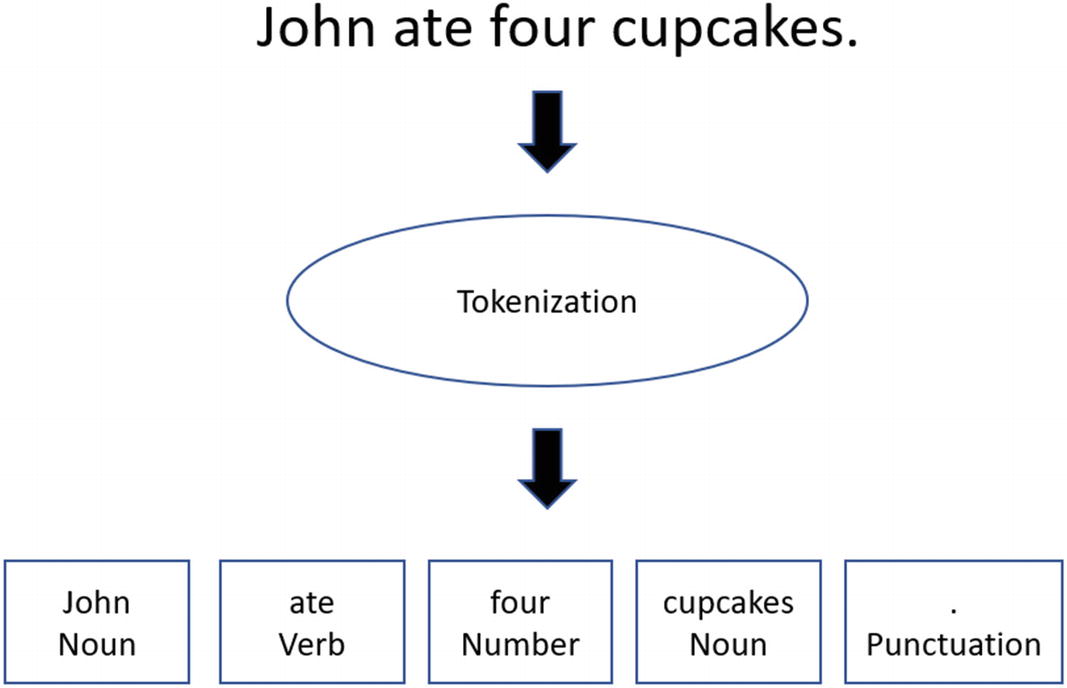
All in all, kind of easy? Kind of.
After tokenization, there will be normalization of the text. This will entail converting some of the text so as to make it easier for analysis, such as by changing the case to upper or lower, removing punctuation, and eliminating contractions.
But this can easily lead to some problems. Suppose we have a sentence that has “A.I.” Should we get rid of the periods? And if so, will the computer know what “A I” means?
Probably not.
Interestingly enough, even the case of words can have a major impact on the meaning. Just look at the difference between “fed” and the “Fed.” The Fed is often another name for the Federal Reserve. Or, in another case, let’s suppose we have “us” and “US.” Are we talking about the United States here?
Here are some of the other issues:
- White Space Problem: This is where two or more words should be one token because the words form a compound phrase. Some examples include “New York” and “Silicon Valley.”
- Scientific Words and Phrases: It’s common for such words to have hyphens, parentheses, and Greek letters. If you strip out these characters, the system may not be able to understand the meanings of the words and phrases.
- Messy Text: Let’s face it, many documents have grammar and spelling errors.
- Sentence Splitting: Words like “Mr.” or “Mrs.” can prematurely end a sentence because of the period.
- Non-important Words: There are ones that really add little or no meaning to a sentence, like “the,” “a,” and “an.” To remove these, you can use a simple Stop Words filter.
As you can see, it can be easy to mis-parse sentences (and in some languages, like Chinese and Japanese, things can get even more difficult with the syntax). But this can have far-ranging consequences. Since tokenization is generally the first step, a couple errors can cascade through the whole NLP process.
Stemming
Stemming describes the process of reducing a word to its root (or lemma), such as by removing affixes and suffixes. This has actually been effective for search engines, which involve the use of clustering to come up with more relevant results. With stemming, it’s possible to find more matches as the word has a broader meaning and even to handle such things as spelling errors. And when using an AI application, it can help improve the overall understanding.
Figure 6-2 shows an example of stemming.
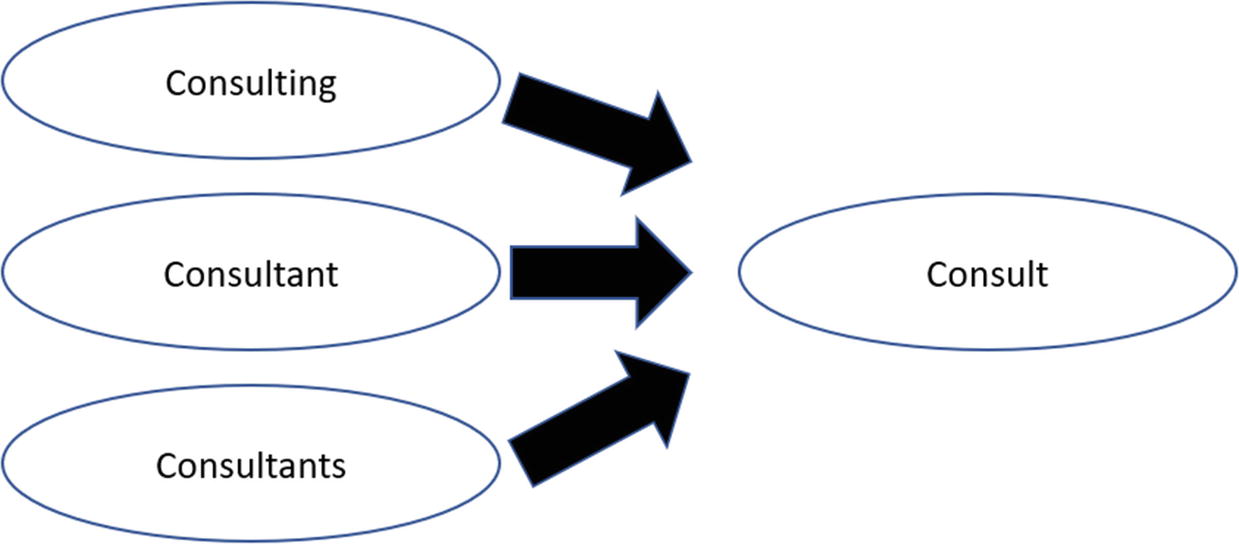
There are a variety of algorithms to stem words, many of which are fairly simple. But they have mixed results. According to IBM:
The Porter algorithm, for example, will state that ‘universal’ has the same stem as ‘university’ and ‘universities,’ an observation that may have historical basis but is no longer semantically relevant. The Porter stemmer also does not recognize that ‘theater’ and ‘theatre’ should belong to the same stem class. For reasons such as these, Watson Explorer Engine does not use the Porter stemmer as its English stemmer.5
In fact, IBM has created its own proprietary stemmer, and it allows for significant customization.
Lemmatization
Lemmatization is similar to stemming. But instead of removing affixes or prefixes, there is a focus on finding similar root words. An example is “better,” which we could lemmatize to “good.” This works so long as the meaning remains mostly the same. In our example, both are roughly similar, but “good” has a clearer meaning. Lemmatization also may work with providing better searches or language understanding, especially with translations.
Figure 6-3 shows an example of lemmatization.
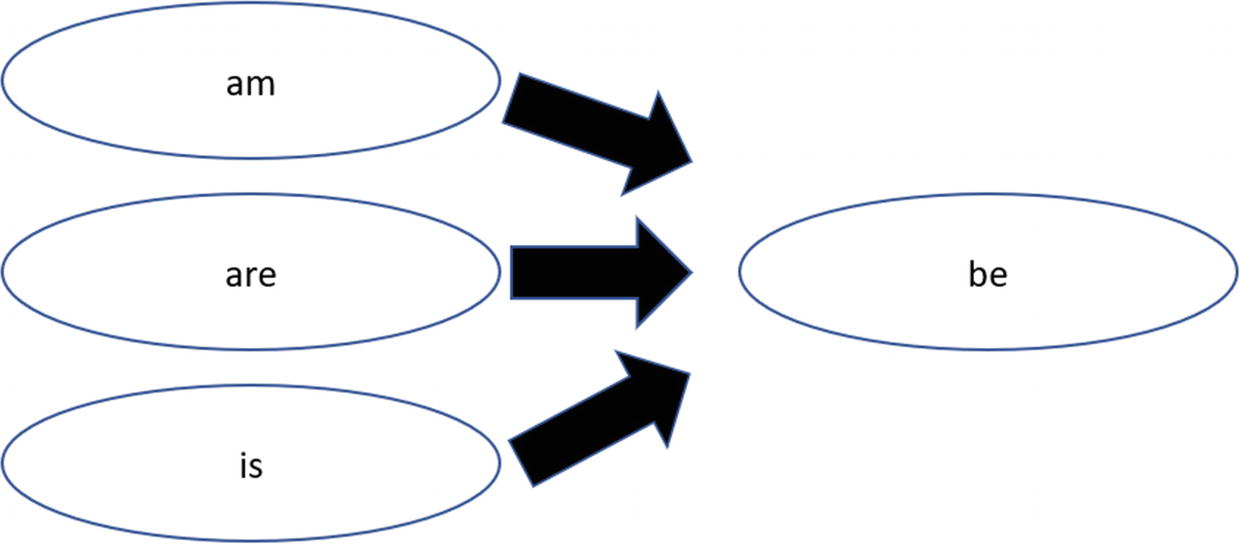
To effectively use lemmatization, the NLP system must understand the meanings of the words and the context. In other words, this process usually has better performance than stemming. On the other hand, it also means that the algorithms are more complicated and there are higher levels of computing power required.
Step #2—Understanding and Generating Language
Once the text has been put into a format that computers can process, then the NLP system must understand the overall meaning. For the most part, this is the hardest part.
But over the years, researchers have developed a myriad of techniques to help out, such as the following:
- Tagging Parts of Speech (POS): This goes through the text and designates each word into its proper grammatical form, say nouns, verbs, adverbs, etc. Think of it like an automated version of your grade school English class! What’s more, some POS systems have variations. Note that a noun has singular nouns (NN), singular proper nouns (NNP), and plural nouns (NNS).
- Chunking: The words will then be analyzed in terms of phrases. For example, a noun phrase (NP) is a noun that acts as the subject or object to a verb.
- Named Entity Recognition: This is identifying words that represent locations, persons, and organizations.
- Topic Modelling: This looks for hidden patterns and clusters in the text. One of the algorithms, called Latent Dirichlet Allocation (LDA), is based on unsupervised learning approaches. That is, there will be random topics assigned, and then the computer will iterate to find matches.
For many of these processes, we can use deep learning models. They can be extended to more areas of analysis—to allow for seamless language understanding and generation. This is a process known as distributional semantics.
With a convolutional neural network (CNN), which we learned about in Chapter 4, you can find clusters of words that are translated into a feature map. This has allowed for applications like language translation, speech recognition, sentiment analysis, and Q&A. In fact, the model can even do things like detect sarcasm!
Yet there are some problems with CNNs. For example, the model has difficulties with text that has dependencies across large distances. But there are some ways to handle this, such as with time-delayed neural networks (TDNN) and dynamic convolutional neural networks (DCNN). These methods have shown high performance in handling sequenced data. Although, the model that has shown more success with this is the recurrent neural network (RNN), as it memorizes data.
So far, we have been focused mostly on text analysis. But for there to be sophisticated NLP, we also must build voice recognition systems. We’ll take a look at this in the next section.
Voice Recognition
In 1952, Bell Labs created the first voice recognition system, called Audrey (for Automatic Digit Recognition). It was able to recognize phonemes, which are the most basic units of sounds in a language. English, for example, has 44.
Audrey could recognize the sound of a digit, from zero to nine. It was accurate for the voice of the machine’s creator, HK Davis, about 90% of the time.6 And for anyone else, it was 70% to 80% or so.
Audrey was a major feat, especially in light of the limited computing power and memory available at the time. But the program also highlighted the major challenges with voice recognition. When we speak, our sentences can be complex and somewhat jumbled. We also generally talk fast—an average of 150 words per minute.
As a result, voice recognition systems improved at a glacially slow pace. In 1962, IBM’s Shoebox system could recognize only 16 words, 10 digits, and 6 mathematical commands.
It was not until the 1980s that there was significant progress in the technology. The key breakthrough was the use of the hidden Markov model (HMM), which was based on sophisticated statistics. For example, if you say the word “dog,” there will be an analysis of the individual sounds d, o, and g. The HMM algorithm will assign a score to each of these. Over time, the system will get better at understanding the sounds and translate them into words.
While HMM was critical, it still was unable to effectively handle continuous speech. For example, voice systems were based on template matching. This involved translating sound waves into numbers, which was done by sampling. The result was that the software would measure the frequency of the intervals and store the results. But there had to be a close match. Because of this, the voice input had to be quite clear and slow. There also had to be little background noise.
But by the 1990s, software developers would make strides and come out with commercial systems, such as Dragon Dictate, which could understand thousands of words in continuous speech. However, adoption was still not mainstream. Many people still found it easier to type into their computers and use the mouse. Yet there were some professions, like medicine (a popular use case with transcribing diagnosis of patients), where speech recognition found high levels of usage.
With the emergence of machine learning and deep learning, voice systems have rapidly become much more sophisticated and accurate. Some of the key algorithms involve the use of the long short-term memory (LSTM), recurrent neural networks, and deep feed-forward neural networks. Google would go on to implement these approaches in Google Voice, which was available to hundreds of millions of smartphone users. And of course, we’ve seen great progress with other offerings like Siri, Alexa, and Cortana.
Leave a Reply