Author: workhouse123
-
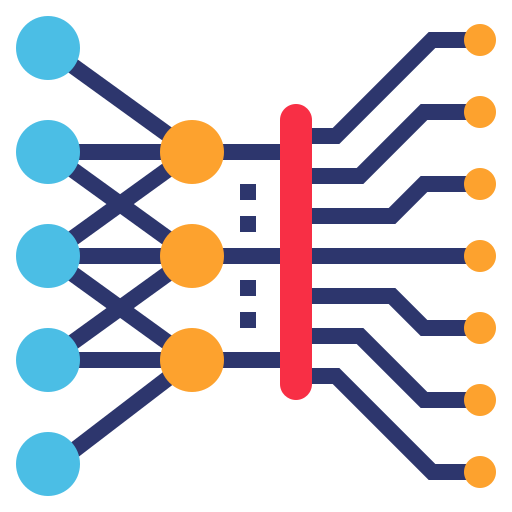
Backpropagation
One of the major drawbacks with artificial neural networks is the process of making adjustments to the weights in the model. Traditional approaches, like the use of the mutation algorithm, used random values that proved to be time consuming. Given this, researchers looked for alternatives, such as backpropagation. This technique had been around since the 1970s but…
-
Artificial Neural Networks (ANNs)
At the most basic level, an artificial neural network (ANN) is a function that includes units (which may also be called neurons, perceptrons, or nodes). Each unit will have a value and a weight, which indicates the relative importance, and will go into the hidden layer. The hidden layer uses a function, with the result…
-
The Brain and Deep Learning
Weighing only about 3.3 pounds, the human brain is an amazing feat of evolution. There are about 86 billion neurons—often called gray matter—that are connected with trillions of synapses. Think of neurons as CPUs (Central Processing Units) that take in data. The learning occurs with the strengthening or weakening of the synapses. The brain is made up…
-
Difference Between Deep Learning and Machine Learning
There is often confusion between deep learning and machine learning. And this is reasonable. Both topics are quite complex, and they do share many similarities. So to understand the differences, let’s first take a look at two high-level aspects of machine learning and how they relate to deep learning. First of all, while both usually…
-

-

Conclusion
These algorithms can get complicated and do require strong technical skills. But it is important to not get too bogged down in the technology. After all, the focus is to find ways to use machine learning to accomplish clear objectives. Again, Stich Fix is a good place to get guidance on this. In the November issue of…
-
K-Means Clustering (Unsupervised/Clustering)
The k-Means clustering algorithm, which is effective for large datasets, puts similar, unlabeled data into different groups. The first step is to select k, which is the number of clusters. To help with this, you can perform visualizations of that data to see if there are noticeable grouping areas. Here’s a look at sample data,…
-
Ensemble Modelling (Supervised Learning/Regression)
Ensemble modelling means using more than one model for your predictions. Even though this increases the complexity, this approach has been shown to generate strong results. To see this in action, take a look at the “Netflix Prize,” which began in 2006. The company announced it would pay $1 million to anyone or any team that…
-
Decision Tree (Supervised Learning/Regression)
No doubt, clustering may not work on some datasets. But the good news is that there are alternatives, such as a decision tree. This approach generally works better with nonnumerical data. The start of a decision tree is the root node, which is at the top of the flow chart. From this point, there will be a tree of decision paths,…
-
Linear Regression (Supervised Learning/Regression)
Linear regression shows the relationship between certain variables. The equation—assuming there is enough quality data—can help predict outcomes based on inputs. Example: Suppose we have data on the number of hours spent studying for an exam and the grade. See Table 3-6. Table 3-6. Chart for hours of study and grades Hours of Study Grade Percentage 1 0.75 1…