Author: workhouse123
-

K-Nearest Neighbor (Supervised Learning/Classification)
The k-Nearest Neighbor (k-NN ) is a method for classifying a dataset (k represents the number of neighbors). The theory is that those values that are close together are likely to be good predictors for a model. Think of it as “Birds of a feather flock together.” A use case for k-NN is the credit score, which is…
-
Naïve Bayes Classifier (Supervised Learning/Classification)
Earlier in this chapter, we looked at Bayes’ theorem. As for machine learning, this has been modified into something called the Naïve Bayes Classifier. It is “naïve” because the assumption is that the variables are independent from each other—that is, the occurrence of one variable has nothing to do with the others. True, this may…
-
Common Types of Machine Learning Algorithms
There is simply not enough room in this book to cover all the machine learning algorithms! Instead, it’s better to focus on the most common ones. In the remaining part of this chapter, we’ll take a look at those for the following: Figure 3-3 shows a general framework for machine learning algorithms.
-
Applying Algorithms
Some algorithms are quite easy to calculate, while others require complex steps and mathematics. The good news is that you usually do not have to compute an algorithm because there are a variety of languages like Python and R that make the process straightforward. As for machine learning, an algorithm is typically different from a traditional…
-
The Machine Learning Process
To be successful with applying machine learning to a problem, it’s important to take a systematic approach. If not, the results could be way off base. First of all, you need to go through a data process, which we covered in the prior chapter. When this is finished, it’s a good idea to do a visualization of…
-
What Can You Do with Machine Learning?
As machine learning has been around for decades, there have been many uses for this powerful technology. It also helps that there are clear benefits, in terms of cost savings, revenue opportunities, and risk monitoring. To give a sense of the myriad applications, here’s a look at some examples: Figure 3-2 shows some of the applications for…
-
Feature Extraction
In Chapter 2, we looked at selecting the variables for a model. The process is often called feature extraction or feature engineering. An example of this would be a computer model that identifies a male or female from a photo. For humans, this is fairly easy and quick. It’s something that is intuitive. But if someone…
-
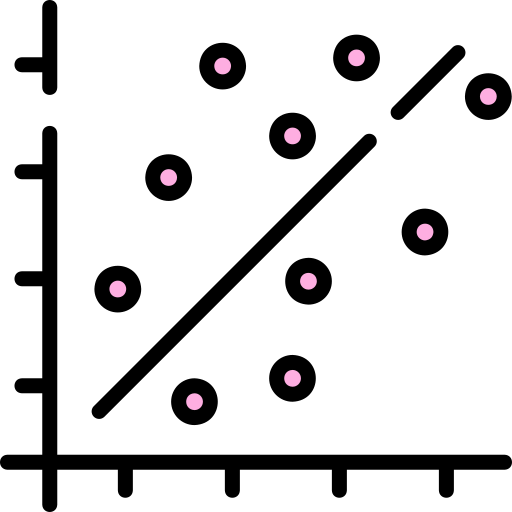
Correlation
A machine learning algorithm often involves some type of correlation among the data. A quantitative way to describe this is to use the Pearson correlation, which shows the strength of the relationship between two variables that range from 1 to –1 (this is the coefficient). Here’s how it works: Then what is a strong correlation? As a general…
-
Bayes’ Theorem
As the name implies, descriptive statistics provides information about your data. We’ve already seen this with such things as averages and standard deviations. But of course, you can go well beyond this—basically, by using the Bayes’ theorem. This approach is common in analyzing medical diseases, in which cause and effect are key—say for FDA (Federal Drug Administration)…
-
The Normal Distribution
When plotted on a graph, the normal distribution looks like a bell (this is why another name for it is the “bell curve”). It represents the sum of probabilities for a variable. Interestingly enough, the normal curve is common in the natural world, as it reflects distributions of such things like height and weight. A…